一起來用 Audio generation
這是OpenAI在2024年10月才發佈的功能,使用的模型是 gpt-4o-audio-preview,能夠支援語音的輸入與輸出
與Realtime API不一樣,他走的還是 /chat/completions,並不是 WebSocket
Audio*** $100.00 / 1M input tokens $200.00 / 1M output tokens
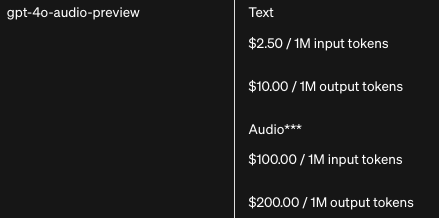
100美金看似很驚人,但其實與 whisper-1 的費用相同
***Audio input costs approximately 6¢ per minute; Audio output costs approximately 24¢ per minute
***語音輸入約每分鐘6美分;語音輸出約每分鐘24美分。
不過我這邊用來做即時的語音翻譯,所以我會專注說明語音輸入 文字輸出的部份
Audio generation
情境:將中文語音轉成日文文字。
{
"model": "gpt-4o-audio-preview",
"modalities": ["text"],
"messages": [
{
"role": "system",
"content": "You are a translation expert. I will ask you to translate a language into setting languages"
},
{
"role": "user",
"content": [
{ "type": "text", text: "將語音,用'jp-JP'完整翻譯,不要發音、注解。" },
{ "type": "input_audio", "input_audio": { "data": base64str, "format": "mp3" } }
]
}
]
}
回應,耗時 2970ms
{
"message": {
"role": "assistant",
"content": "皆さん、こんばんは。私のチャンネルへようこそ。",
"refusal": null
},
"usage": {
"prompt_tokens": 100,
"completion_tokens": 15,
"total_tokens": 115,
}
}
這個用法與Whisper API幾乎是一模一樣,但下面是我踩到的坑!!
- Whisper是支援 webm 或 ogg等5~6種語音格式,但
gpt-4o-audio-preview只有支援mp3與wav
這意味,在瀏覽器上無法直接使用,必需轉檔。
- 使用base64做為audio input,你還必須刪掉wav的base64的頭部meta
base64data.split(',')[1]
情境:需要將中文語音,翻譯成指定的多個語系,並使用Function Calling。
{
"model": "gpt-4o-audio-preview",
"modalities": ["text"],
"messages": [
{
"role": "system",
"content": "You are a translation expert. I will ask you to translate a language into setting languages"
},
{
"role": "user",
"content": [
{ "type": "text", text: "將語音,請翻譯成'zh-CN簡體中文' 'jp-JP日本語' 'en-US美式英文' 完整翻譯,不要發音、注解。" },
{ "type": "input_audio", "input_audio": { "data": base64str, "format": "mp3" } }
]
}
],
"tools": [
{
"type": "function",
"function": {
"name": "split_text",
"description": "Identify Chinese and other languages in text.",
"parameters": {
"type": "object",
"properties": {
"zh-CN": {
"type": "string",
"description": "Chinese reslut"
},
"jp-JP": {
"type": "string",
"description": "Japanese reslut"
},
"en-US": {
"type": "string",
"description": "English reslut"
}
},
"required": [
"zh-CN"
]
}
}
}
],
"tool_choice": "auto"
}
輸出,耗時4970ms
{
"message": {
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_dAdfaFvPBoL4JrgL4QRphIfo",
"type": "function",
"function": {
"name": "split_text",
"arguments": "{\"zh-CN\": \"大家好,今天是10月21号,星期一,欢迎来到我们的节目。\"}"
}
},
{
"id": "call_HnffYc7jMsIZntdBBhPbgrsp",
"type": "function",
"function": {
"name": "split_text",
"arguments": "{\"jp-JP\": \"皆さん、こんにちは。 今日は10月21日、月曜日です。 私たちのプログラムへようこそ。\"}"
}
},
{
"id": "call_VfDkfyBKwKzxRHkNjLyyqnd7",
"type": "function",
"function": {
"name": "split_text",
"arguments": "{\"en-US\": \"Hello everyone, today is October 21st, Monday. Welcome to our show.\"}"
}
}
],
"refusal": null
},
"usage": {
"prompt_tokens": 188,
"completion_tokens": 123,
"total_tokens": 311,
}
}
Function Calling是有支援的,跟前面的實驗一樣,輸出的結果還是有所不同
但Function Calling的彈性很大,應該可以完成不少有趣的開發
情境:使用Structured Outputs,將翻譯結果指定為多個語系。
{
"model": "gpt-4o-audio-preview",
"modalities": ["text"],
"messages": [
{
"role": "system",
"content": "You are a translation expert. I will ask you to translate a language into setting languages"
},
{
"role": "user",
"content": [
{ "type": "text", text: "將語音,用完整翻譯,不要發音、注解。" },
{ "type": "input_audio", "input_audio": { "data": base64str, "format": "mp3" } }
]
}
],
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "split_text",
"schema": {
"type": "object",
"properties": {
"zh-CN": {
"type": "string",
"description": "Chinese reslut"
},
"jp-JP": {
"type": "string",
"description": "Japanese reslut"
},
"en-US": {
"type": "string",
"description": "Englisg reslut"
}
},
"required": [
"zh-CN"
]
}
}
}
}
上面是照著 Structured Outputs 實驗文章的做法,把語音的結果轉成我要的多語系翻譯
來看輸出,耗時339ms
{
"error": {
"message": "Invalid parameter: 'response_format' of type 'json_schema' is not supported with this model. Learn more about supported models at the Structured Outputs guide: https://platform.openai.com/docs/guides/structured-outputs",
"type": "invalid_request_error",
"param": null,
"code": null
}
}
理想很豐滿,現實很骨感…
gpt-4o-audio-preview 並不支援新的 Structured Outputs 結構
結論
傳統的作法是 先用 whisper將語音轉成文字後再呼叫LLM模型。
Audio generation 則是直接讓語音進入OpenAI當下就執行LLM模型,直接是快上一步。
不過,就我開發的過程來看,有兩個大缺點要改善
-
不能支援webm,就是個硬傷。轉成mp3或wav再上傳,不僅讓語音檔案變大,還要等轉檔的時間
-
Structured Outputs居然沒有支援,你是GPT-4o家族的模型為什麼不能用?!
期待這兩個缺點能快快修正,這樣我的即時語音翻譯可以再快一點點!